Ohne Visualisierungstechniken keine Kommunikation mehr möglich
Die wahrscheinlich populärste Form zur Darstellung von strukturierten Daten, also nicht unbedingt Freitext, ist tabellarisch. Tabellen sind durch ihre Zeilen und Spalten charakterisiert, einfach zu verstehen. Auf der anderen Seite sind sie dann aber doch wieder sehr in ihrer eigenen Struktur eingeschränkt. Es ist mitunter oft nicht einfach die Beziehungen zwischen den Zeilen bzw. Zellen herauszulesen.
Durch den Einsatz von geeigneten Visualisierungstechniken kann man im Vergleich nicht nur die Daten selbst, also Attribute und Werte, sondern auch Beziehungen, sofern vorhanden, untereinander darstellen. Auch der ORF setzt wie bei der Berichterstattung der vergangenen Bundespräsidentenwahl immer wieder geeignete Visualisierungstechniken ein – und die Wählerstromanalyse scheint dabei eigentlich immer auf. Man kann Sie ganz gezielt nutzen um das Wahlverhalten von Altersgruppen, Geschlecht oder Berufsgruppen darzustellen.
In Tomo beruht die Datenstruktur vorallem auf Graphen, die aus Knoten und Kanten bestehen. Die Wahl der Darstellung hängt hier sehr stark von den Benutzeranforderungen ab. Generell gelten diese Faustregeln: Sind Beziehungen über längere Pfade wichtig, so ist eine Visualisierung mittels “Node-Link Diagram” vorzuziehen. Große Datenmengen wie es in sozialen Netzwerken der Fall ist können bis zu einer bestimmten Komplexität als Node-Link Diagram dargestellt werden, müssen aber bei enormer Größe oft in Cluster zusammengefasst oder in Ihrer Dimension reduziert werden. Hier bieten sich zum Beispiel “Parallele Koordinaten” aber auch “Scatterplot”-Matrizen an. Muss man hierarchische Strukturen handhaben, dann sind “Treemaps” ein idealer Kandidat. Nie ist aber eine einzige Repräsentation ausschließlich die Richtige, daher werden immer wieder auch hybride Ansätze, eine Mischform mehrfacher Visualisierungstypen, herangezogen.
 Automatische Datenanalyse
Automatische Datenanalyse
Visual Analytics
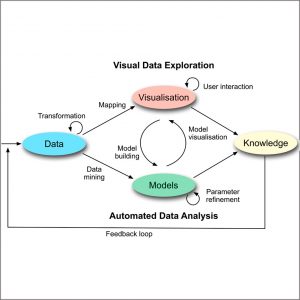
Visualisierung im Generellen steht in enger Verbindung mit dem noch jungen Forschungsgebiet “Visual Analytics”. Das menschliche Gehirn ist Experte bei der Muster- und Merkmalserkennung. Schließlich gilt es Hypothesen aufzustellen und Schlüsse zu ziehen, für welche Computer-unterstütze Algorithmen oft nicht in der Lage sind. Wo Data/Text Mining nicht die nötigen Resultate liefert, nutzt man die menschliche Wahrnehmung. Die Wahrnehmung ist also der Grundstein für die visuelle Datenanalyse, welche nur durch die geeignete Visualisierungstechnik Erkentnisse liefern kann. Daniel Keim zeigt in sehr renomierten Buch “VisMaster: Visual Analytics – Mastering the Information Age” (http://www.vismaster.eu/book/) ganz klar den nötigen Verbund von beiden Komponenten, der visuellen Datenerforschung sowie der automatisierten Datenanalyse, auf.
Grafik 1: Der “Visual Analytics Process” illustriert das enge Zusammenspiel von visueller und automatisierter Datenanalyse. (Grafik von http://www.vismaster.eu/book/ [Keim 2010].)


